Assignment 1: Build Your Own LLaMa
Type: Individual Assignment
Released: Tuesday, September 9
Due: Thursday, September 25 at 11:59 PM

Summary
In this assignment, you will implement core components of the Llama2 transformer architecture to gain hands-on experience with modern language modeling. You will build a minimalist version of Llama2 and apply it to text continuation and sentence classification tasks.
- Collaboration Policy: Please read the collaboration policy here: https://cmu-l3.github.io/anlp-fall2025/
- Late Submission Policy: See the late submission policy here: https://cmu-l3.github.io/anlp-fall2025/
- Submitting your work: You will use Canvas to submit your implementation files and output results. Please follow the submission instructions carefully to ensure proper grading. See the submission guidelines here: https://github.com/cmu-l3/anlp-fall2025-hw1
1. Overview
This assignment focuses on implementing core components of the Llama2 transformer architecture to give you hands-on experience with modern language modeling techniques. You will build a mini version of Llama2 and apply it to text continuation and sentence classification tasks.
The assignment consists of two main parts:
Part 1: Core Implementation. In this part, you will complete the missing components of the Llama2 model architecture. Specifically, implement:
- Attention mechanisms
- Feed-forward networks
- Layer normalization (LayerNorm)
- Positional encodings (RoPE)
- Optimizer implementation (AdamW)
- LoRA (Low-Rank Adaptation)
Part 2: Applications. After completing the core implementation, apply your model to the following tasks:
- Text Generation – generate coherent continuations for given prompts.
- Zero-shot Classification – classify inputs without task-specific fine-tuning.
- Fine-tuning – train the model on downstream tasks to improve performance.
- LoRA Fine-tuning – apply parameter-efficient training using Low-Rank Adaptation.
- Advanced Methods (Bonus) – explore creative or research-level improvements for additional credit.
2. Understanding Llama2 Architecture
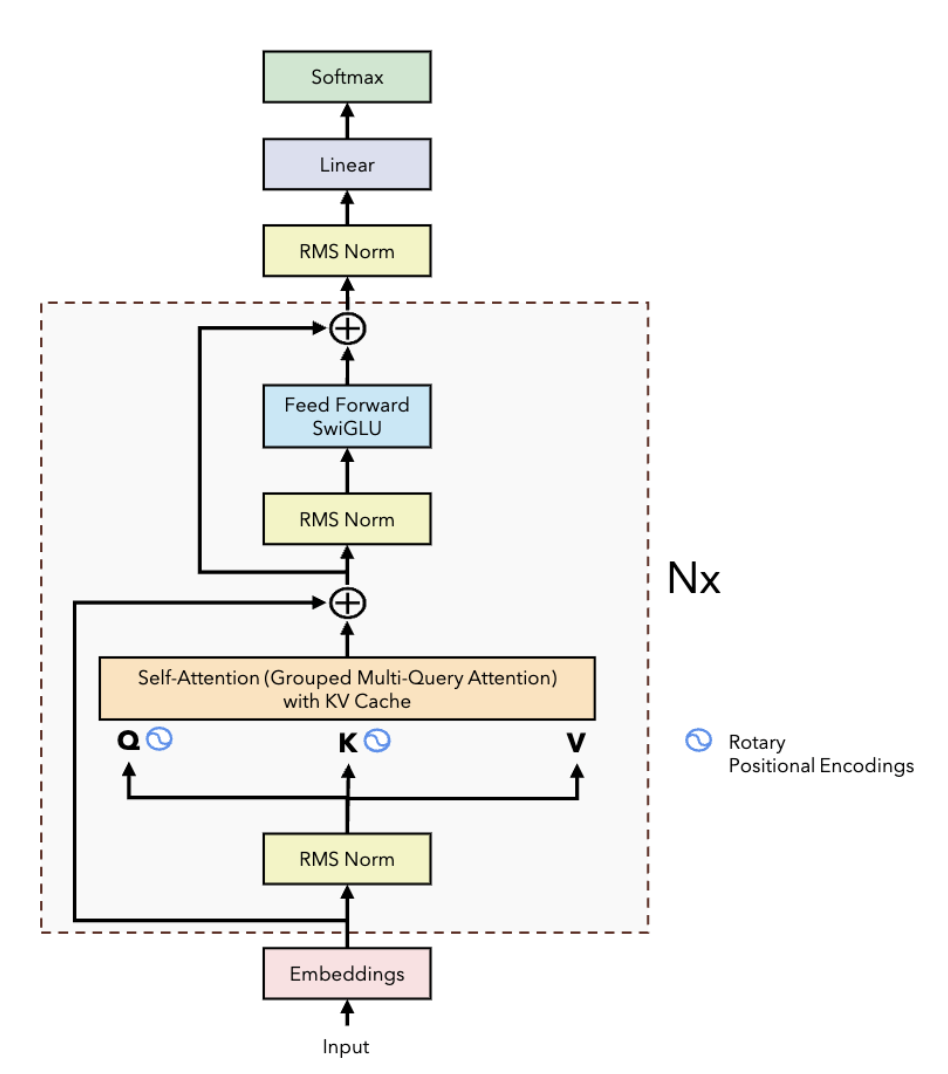
Figure 1: LLaMA Architecture Overview showing the transformer-based structure with RMSNorm pre-normalization, SwiGLU activation function, rotary positional embeddings (RoPE), and grouped-query attention (GQA).
Sources:
PyTorch LLaMA Implementation Notes and
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama2 is a transformer-based language model that improves on the original Llama architecture with enhanced performance and efficiency. Its key features include RMSNorm pre-normalization, SwiGLU activation, rotary positional embeddings (RoPE), and grouped-query attention (GQA). In this assignment, you will implement several of these components, which are explained below.
In this assignment, you will implement the following core components:
1. LayerNorm (Layer Normalization)
In this assignment, we will use LayerNorm instead of RMSNorm (which is used in Llama2). You will implement LayerNorm in llama.py. This normalization operates across features for each data point, reducing internal covariate shift, stabilizing gradients, and accelerating training.
Here, āi is the normalized input, g is a learnable gain, and μ, σ are the mean and standard deviation of inputs a:
LayerNorm makes activations independent of input scale and weights to improve stability.
2. Scaled Dot-Product Attention and Grouped Query Attention
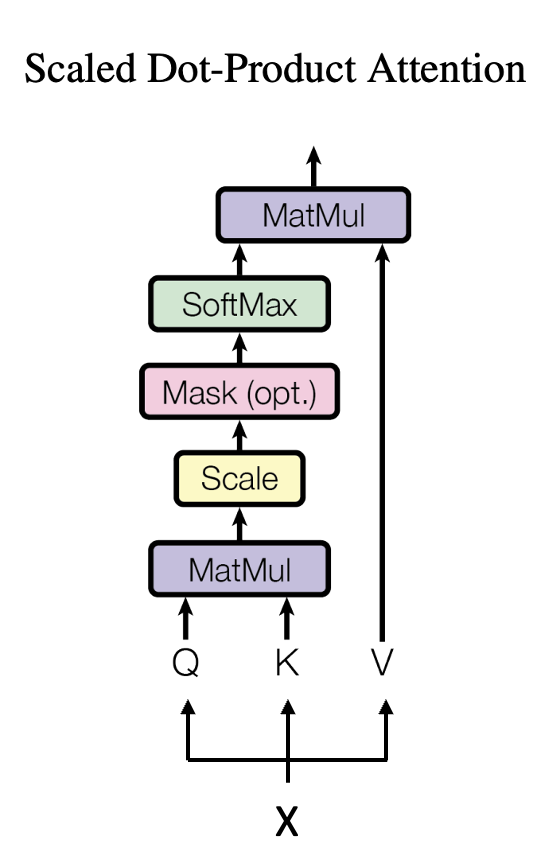
Scaled Dot-Product Attention is the fundamental building block of the Transformer architecture (Vaswani et al., 2017). It computes attention scores by comparing queries (Q) with keys (K). These scores determine how much focus each token should place on other tokens, and are then used to weight the values (V). To prevent large dot products from destabilizing training, the scores are scaled by the square root of the key dimension before applying the softmax function:
In this assignment, you will implement the scaled dot-product attention mechanism in the function
compute_query_key_value_scores within llama.py.
The diagram below (Figure 2a) shows the high-level process: Q and K are multiplied, scaled,
optionally masked (to prevent attending to certain positions), and normalized with softmax
before being applied to V.
In self-attention, the same input embeddings X are projected into queries (Q), keys (K), and values (V) using learned weight matrices (WQ, WK, WV). These separate projections allow the model to learn different views of each token depending on whether it is acting as a query, a key, or a value. Once Q, K, and V are obtained, the self-attention mechanism compares every query with all keys to produce attention scores, which are then used to weight the corresponding values.
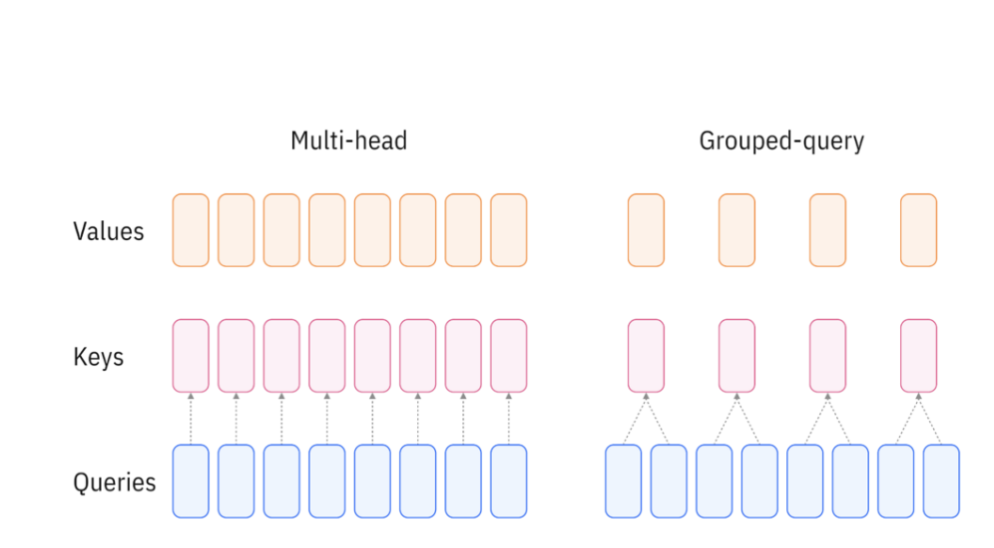
In practice, a single self-attention head may not capture all types of relationships in a sequence. To address this, Multi-Head Attention (MHA) runs several independent self-attention operations in parallel and concatenates their results. This allows the model to attend to information from multiple subspaces simultaneously, greatly enriching its representations. However, computing full attention for many heads becomes costly at scale. Grouped Query Attention (GQA) was introduced to reduce this overhead (Ainslie et al., 2023). Instead of giving each query its own key-value pair, multiple queries are grouped together and share the same K and V projections. Figure 2b shows how GQA works
3. RoPE Embeddings (Rotary Positional Embeddings)
Rotary Positional Embeddings (RoPE) are currently used in LLMs such as Llama. The technique employs a rotation matrix with a hyperparameter theta to rotate key and query vectors based on their position in a sequence, encoding positional information by rotating token embeddings in 2D space. In this assignment, you will implement RoPE in the function apply_rotary_emb within rope.py.
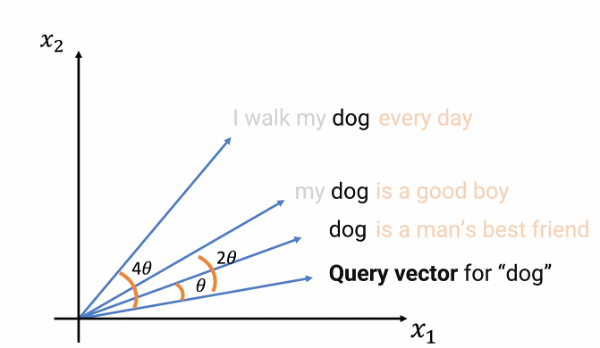
Figure 3a: RoPE Overview showing the rotary positional embedding technique for the word "dog" in different positions. Figure from How Rotary Position Embedding Supercharges Modern LLMs..
As shown in the diagrams, the word "dog" is rotated based on its position. For example, in the sentence "I walk my dog every day," it is rotated by 4θ; in "my dog is a good boy," by 2θ; and in "dog is a man's best friend," by θ. In general, a rotation transformation is applied to query and key vectors before computing attention scores.

Figure 3b: Rotation Matrix for Rotary Positional Embedding.
The rotation matrix, though complex-looking, applies different theta values to each pair of dimensions, which are then combined. This hyperparameter theta allows RoPE to extend sequence length post-training, enabling the use of longer sequences during inference by simply rotating the key and query vectors.
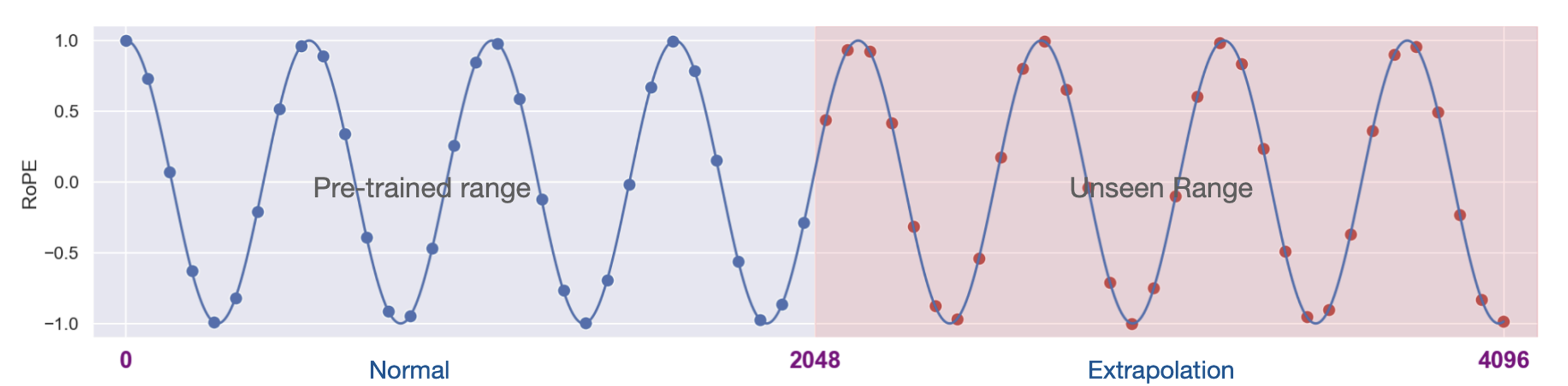
Figure 3c: RoPE extrapolation for unseen positions.
4. LoRA Low-Rank Adaptation
The basic idea of LoRA is to add low-rank matrices with dimensions smaller than the original weight matrix, training only these LoRA adaptors instead of the entire model. After training, these adaptors are added to the original weight matrix. These low-rank matrices have reduced dimensions, and when multiplied after training, they match the original weight matrix's dimensions, allowing straightforward addition.
For a pre-trained weight matrix W₀ ∈ ℝᵈˣᵏ, LoRA constrains the update by representing it with a low-rank decomposition: W₀ + ΔW = W₀ + BA, where B ∈ ℝᵈˣʳ, A ∈ ℝʳˣᵏ, and the rank r ≪ min(d, k). During training, W₀ is frozen while A and B contain trainable parameters.
The modified forward pass becomes: h = W₀x + ΔWx = W₀x + BAx. LoRA output BAx is scaled by α/r before being added to the original output, where α is a constant and r is the rank. This gives us the final computation: h = W₀x + (α/r) × BAx.
In transformer architectures, LoRA adaptors are typically injected into the Query and Value weight matrices. The rank R is usually set to 16, 8 or 4, depending on the model size and fine-tuning task. For larger models or more challenging tasks, R can be increased to 64 or higher. In this assignment, you will implement LoRALayer within lora.py.
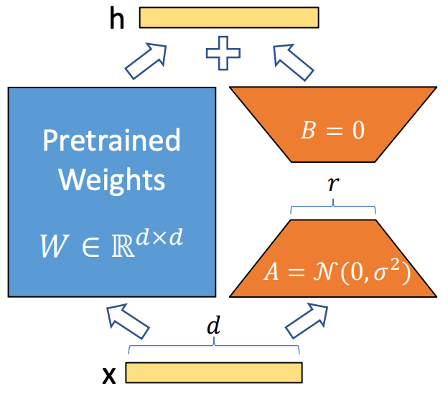
Figure 4: LoRA Overview - Illustration of Low-Rank Adaptation Technique for Efficient Model Fine-Tuning.
5. AdamW Optimizer
AdamW is an improved version of the Adam optimizer that decouples weight decay from gradient-based updates,
leading to better regularization and improved generalization performance in transformer models. This optimizer
is widely used in training large language models due to its superior convergence properties. In this assignment, you will implement the AdamW algorithm (Algorithm 2 in Loshchilov & Hutter, 2017, shown below)
inside the optimizer.py.

For detailed explaination, mathematical formulations and pseudocode, refer to the referenced papers.
6. Epsilon Sampling Decoding
Epsilon sampling is a text generation strategy that filters out tokens with probability below a fixed threshold (ε),
then samples from the remaining tokens. This approach provides a simple yet effective way to balance diversity
and quality in generated text by removing very low-probability tokens that might lead to incoherent outputs. You will implement epsilon sampling in the function generate within llama.py.
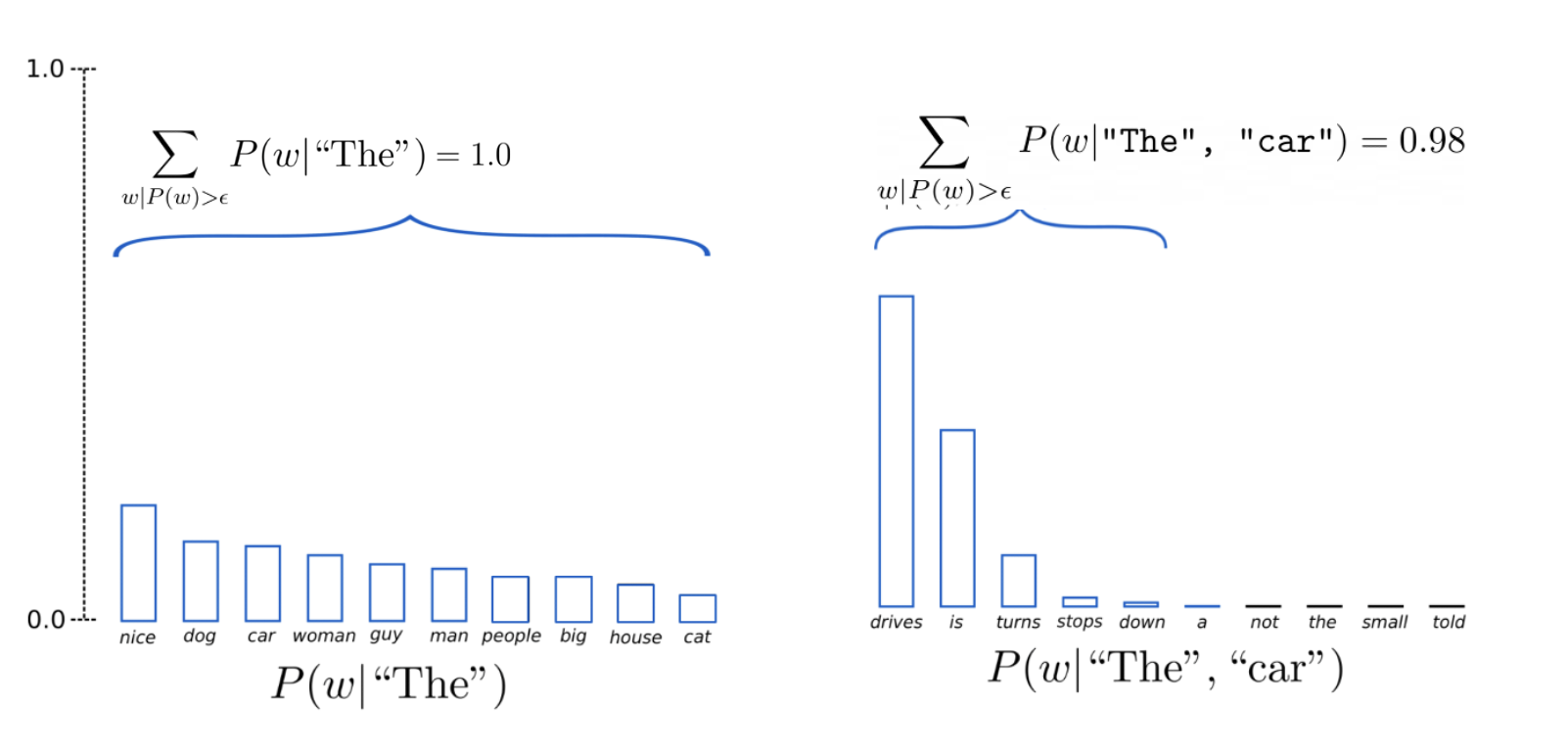
Figure 6: Epsilon Sampling Overview showing the advanced decoding technique for text generation. Figure from Inference Algorithms for Language Modeling.
3. Tasks and Datasets
After implementing the core components from Part 1 (attention mechanisms, feed-forward networks, layer normalization, RoPE, optimizer, and LoRA), you will test your model across three main tasks: (1) text continuation where you'll complete prompts to produce coherent continuations, (2) sentiment classification on two movie review datasets - the Stanford Sentiment Treebank (SST) for 5-class sentiment analysis of single sentences from movie reviews, and CFIMDB for binary sentiment classification of full movie reviews, and (3) evaluation across three settings - zero-shot prompting (using the pretrained model directly with crafted prompts), full fine-tuning (adapting the entire model through gradient updates), and LoRA fine-tuning (parameter-efficient adaptation using low-rank matrices). You'll measure performance through classification accuracy on the sentiment tasks.
Implementation Details
For detailed instructions on how to run these tasks, including setup procedures, command-line arguments, and execution steps, please refer to the GitHub repository for this assignment: https://github.com/cmu-l3/anlp-fall2025-hw1. The repository contains comprehensive documentation and example scripts to help you successfully complete each task.
4. Advanced Methods
To qualify for an A+, you must go beyond the basic requirements (i.e., an A-level submission) by implementing additional methods that deliver accuracy improvements or demonstrate exceptional creativity. These enhancements can be in either the zero-shot setting (no task-specific fine-tuning required) or the fine-tuning setting (improving upon the current implementation). Your work must be executable using the specified commands, and you are required to submit a detailed report that documents your implementations, experiments, and provides clear instructions for reproduction. Without the report, you will not be eligible for an A+. Example directions include: performing continued pre-training for domain adaptation, enabling zero-shot prompting with more principled inference (e.g., fixing attention masking for right-padded batches), or experimenting with alternative decoding mechanisms (at least two beyond the baseline). Other possibilities include prompt-based fine-tuning, parameter-efficient fine-tuning, or alternative optimization approaches such as SMART or WiSE-FT. You may also add model enhancements such as new components, improved positional encodings (e.g., rotary or other replacements), or alternative attention mechanisms such as sparse attention or the Differential Transformer. In addition to the code and report, providing scripts (e.g., shell commands) and logs for reproducibility is strongly encouraged. All submissions must be your own work; while you may use publicly available resources and code, proper attribution is required (see CMU’s academic integrity policy).
5. Submission Instructions and Grading
For comprehensive submission instructions and grading criteria, please refer to the assignment GitHub repository.