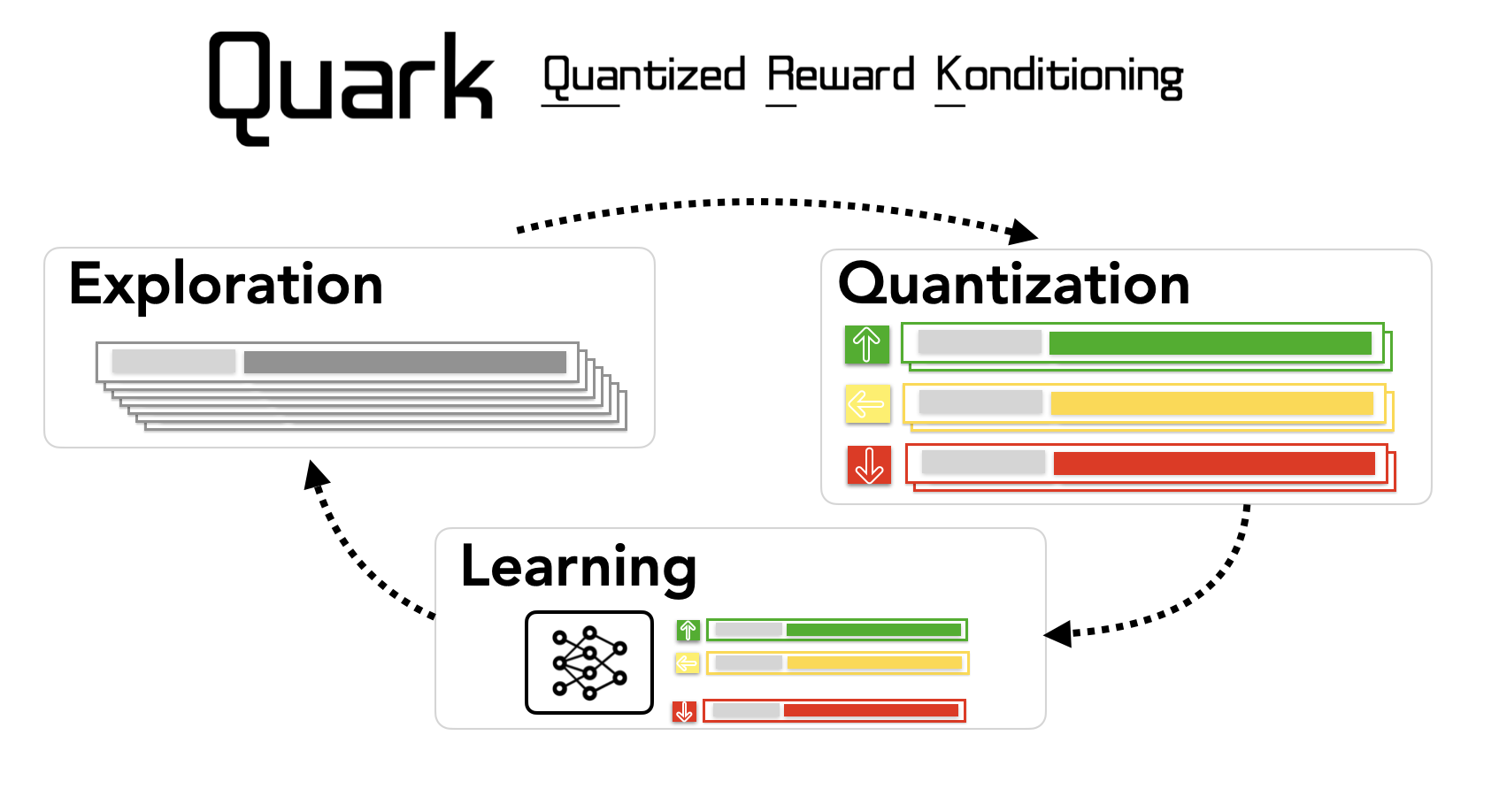
Left: Quantized Reward Konditioning (Quark); Right: Unlikelihood training.
Related publications
2024
-
Zhiqing Sun, Longhui Yu, Yikang Shen, and 4 more authors
In Advances in Neural Information Processing Systems, 09–15 jun 2024
2023
-
Ximing Lu, Faeze Brahman, Peter West, and 14 more authors
EMNLP, 09–15 jun 2023
-
Skyler Hallinan, Faeze Brahman, Ximing Lu, and 3 more authors
EMNLP Findings, 09–15 jun 2023
-
Sean Welleck, Ximing Lu, Peter West, and 4 more authors
In The Eleventh International Conference on Learning Representations , 09–15 jun 2023
2022
-
Jiacheng Liu, Skyler Hallinan, Ximing Lu, and 4 more authors
In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Dec 2022
Knowledge underpins reasoning. Recent research demonstrates that when relevant knowledge is provided as additional context to commonsense question answering (QA), it can substantially enhance the performance even on top of state-of-the-art. The fundamental challenge is where and how to find such knowledge that is high quality and on point with respect to the question; knowledge retrieved from knowledge bases are incomplete and knowledge generated from language models are inconsistent. We present Rainier, or Reinforced Knowledge Introspector, that learns to generate contextually relevant knowledge in response to given questions. Our approach starts by imitating knowledge generated by GPT-3, then learns to generate its own knowledge via reinforcement learning where rewards are shaped based on the increased performance on the resulting question answering. Rainier demonstrates substantial and consistent performance gains when tested over 9 different commonsense benchmarks: including 5 datasets that are seen during model training, as well as 4 datasets that are kept unseen. Our work is the first to report that knowledge generated by models that are orders of magnitude smaller than GPT-3, even without direct supervision on the knowledge itself, can exceed the quality of commonsense knowledge elicited from GPT-3.
-
Ximing Lu, Sean Welleck, Jack Hessel, and 5 more authors
In Advances in Neural Information Processing Systems, Dec 2022
NeurIPS 2022 Oral
2020
-
Sean Welleck, and Kyunghyun Cho
In AAAI Conference on Artificial Intelligence, Dec 2020
-
Margaret Li, Stephen Roller, Ilia Kulikov, and 4 more authors
In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 2020
Generative dialogue models currently suffer from a number of problems which standard maximum likelihood training does not address. They tend to produce generations that (i) rely too much on copying from the context, (ii) contain repetitions within utterances, (iii) overuse frequent words, and (iv) at a deeper level, contain logical flaws. In this work we show how all of these problems can be addressed by extending the recently introduced unlikelihood loss (Welleck et al., 2019) to these cases. We show that appropriate loss functions which regularize generated outputs to match human distributions are effective for the first three issues. For the last important general issue, we show applying unlikelihood to collected data of what a model should not do is effective for improving logical consistency, potentially paving the way to generative models with greater reasoning ability. We demonstrate the efficacy of our approach across several dialogue tasks.
-
Sean Welleck, Ilia Kulikov, Stephen Roller, and 3 more authors
In International Conference on Learning Representations, Jul 2020